SpringMVC 启动过程
SpringMVC 启动的过程大致可以分为三个大的阶段:应用容器的初始化、Spring 父子容器的加载、SpringMVC 组件注册。
一:应用容器的初始化
Tomcat启动与SPI发现
在全注解模式下,启动不再依赖 web.xml。
- Servlet 容器启动:当你运行 catalina.sh run,Tomcat 开始加载你的 WAR 包。
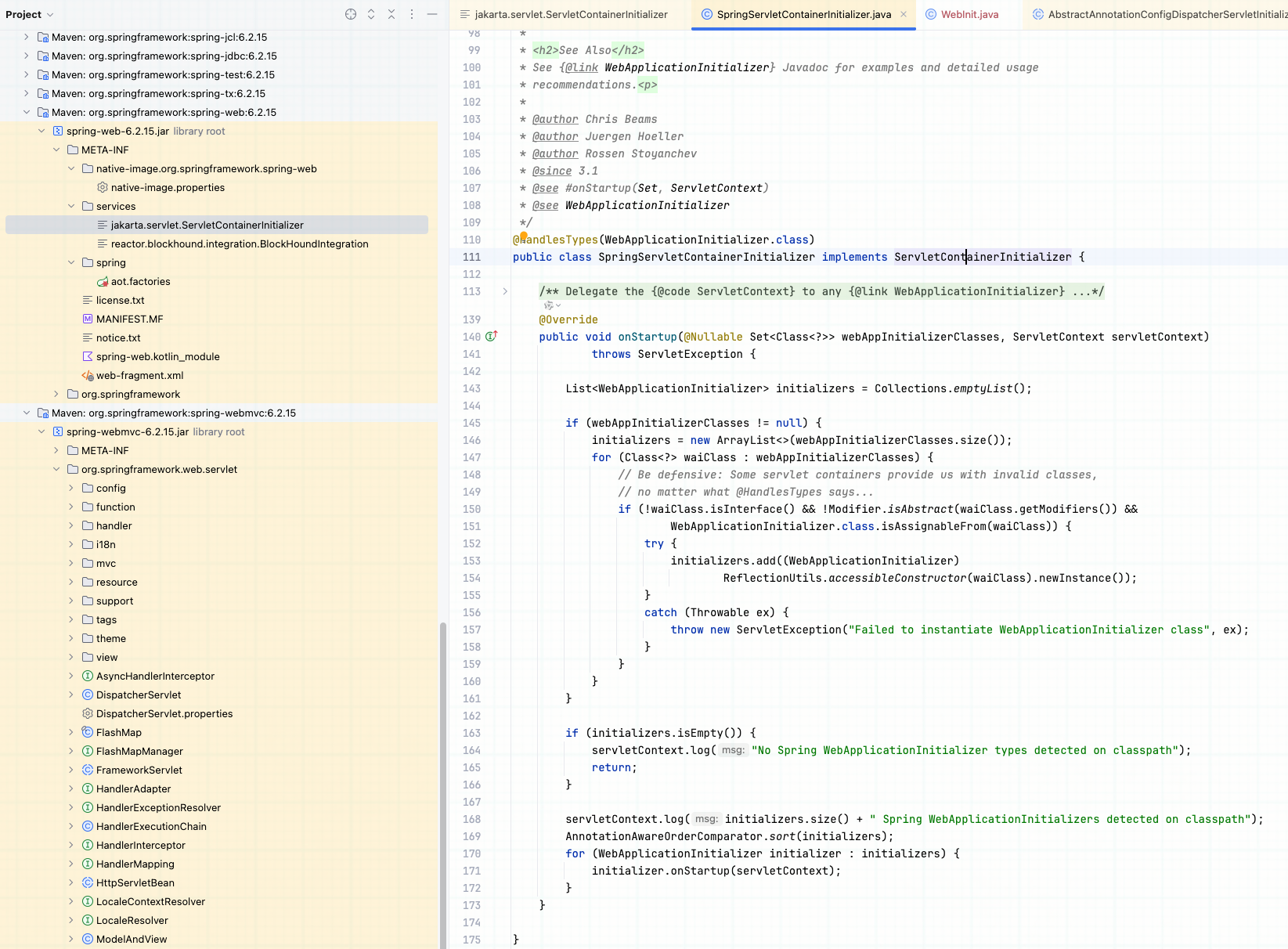
- SPI 机制扫描:Spring 的 spring-web 包下有一个文件 META-INF/services/jakarta.servlet.ServletContainerInitializer,里面指向了 SpringServletContainerInitializer。
- 寻找初始化器:Tomcat 会调用这个类,它会扫描你项目中所有实现了 WebApplicationInitializer 接口的类。
还记得之前我们写的 WebInit 吗?我们正是通过这个类,将原来的 web.xml 完全替代。在这类中我们注册 RootConfig、WebMvcConfig,Filters、DispatcherServlet 等等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
public class WebInit extends AbstractAnnotationConfigDispatcherServletInitializer {
@Override
protected Class<?>[] getRootConfigClasses() {
return new Class[] { RootConfig.class };
}
@Override
protected Class<?>[] getServletConfigClasses() {
return new Class[] { WebMvcConfig.class };
}
@Override
protected Filter[] getServletFilters() {
CharacterEncodingFilter encodingFilter = new CharacterEncodingFilter();
encodingFilter.setEncoding("UTF-8");
encodingFilter.setForceResponseEncoding(true);
HiddenHttpMethodFilter hiddenHttpMethodFilter = new HiddenHttpMethodFilter();
return new Filter[]{encodingFilter, hiddenHttpMethodFilter};
}
@Override
protected String[] getServletMappings() {
return new String[] { "/" };
}
@Override
protected void customizeRegistration(jakarta.servlet.ServletRegistration.Dynamic registration) {
registration.setInitParameter("throwExceptionIfNoHandlerFound", "true");
registration.setMultipartConfig(new jakarta.servlet.MultipartConfigElement("", 2097152, 4194304, 0));
super.customizeRegistration(registration);
}
}
|
SPI机制原理和案例
Spring MVC 之所以能实现 “零 XML 启动”,全靠 Java 原生的 SPI 机制。SPI 实际上是一种服务发现机制。它将 “接口定义” 和 “具体实现” 解耦,由第三方将插件式的代码注入到主程序中。它的核心逻辑只有三步:
- 定义标准接口:主程序提供一个接口。
- 编写注册实现类:实现在自己的项目路径
META-INF/services/ 下创建一个以 “接口全类名” 命名的文件,内容是 “实现类的全类名”。
- 动态加载我们的实现:主程序使用
java.util.ServiceLoader 动态扫描并实例化这些类。
比如我们的系统需要支持多种翻译引擎,我们作为主程序来定义接口,不同的第三方可以有它们自己的实现,只需要通过 “接口”,就可以无缝插入到我们的主程序中来。
第一步:定义接口 (Service Interface)
1
2
3
| public interface Translator {
String translate(String text);
}
|
第二步:编写具体实现 (Service Provider)
1
2
3
4
5
6
| public class BaiduTranslator implements Translator {
@Override
public String translate(String text) {
return "Baidu: " + text + " -> 翻译完成";
}
}
|
第三步:关键——配置 SPI 文件
在项目的资源目录 src/main/resources 下手动创建文件夹和文件:
1
2
3
| 目录:META-INF/services/
文件名:com.demo.spi.Translator(必须是接口的全类名)
文件内容:com.demo.spi.impl.BaiduTranslator(实现类的全类名)
|
第四步:测试加载 (ServiceLoader)
1
2
3
4
5
6
7
8
9
| public static void main(String[] args) {
ServiceLoader<Translator> translators = ServiceLoader.load(Translator.class);
for (Translator t : translators) {
System.out.println("加载到实现类:" + t.getClass().getName());
System.out.println(t.translate("Hello SPI"));
}
}
|
Tomcat(或任何 Servlet 容器)在启动时会寻找 jakarta.servlet.ServletContainerInitializer 的实现。
- Spring-web 包里预设了 META-INF/services/jakarta.servlet.ServletContainerInitializer。
- 内容指向了 Spring 的 SpringServletContainerInitializer。
- 这个类会寻找所有的 WebApplicationInitializer。于是我们的 WebInit 就这样被 Spring 发现并运行了!
你可能会觉得这和策略模式很像。区别在于策略模式需要在代码里手动 new 一个具体的策略对象传给上下文。而程序根本不知道有哪些实现类,只有在运行时扫描 classpath 才知道,SPI 才是真正的 “插件化”。
Java 原生 SPI 有个缺点:它会一次性实例化所有实现类,且不支持依赖注入。这也是为什么 Dubbo 和 Spring 都对其进行了改造(例如 Spring 的 SpringFactoriesLoader)。
二:Spring 父子容器的加载
这是 Spring MVC 最精妙的 “双容器” 设计。为什么要有父子容器呢?主要是为了分层解耦,防止 Web 层的配置污染业务层,并且如果你有两个 DispatcherServlet(例如一个处理 API,一个处理后台管理),它们可以共享同一个父容器中的数据库连接,而各自拥有独立的拦截器和视图解析器。当 Tomcat 通过 SPI 机制找到并运行 Spring 的 SpringServletContainerInitializer 时,它会调用所有 WebApplicationInitializer 实现类的 onStartup(ServletContext) 方法。请记住,一切都是从这个方法开始的!
Spring MVC 源码级启动调用链
1.1 宿主环境启动 (Tomcat)
Tomcat StandardContext.startInternal()
➔ 扫描所有 jar 包下的 META-INF/services/jakarta.servlet.ServletContainerInitializer
▼
1.2 Spring SPI 激活 (Spring-Web)
SpringServletContainerInitializer.onStartup(Set<Class<?>> webAppInitializerClasses, ServletContext ctx)
➔ 获取到我们定义的 WebInit.class,循环调用其 onStartup(ctx)
▼
2. 注册组件 (AbstractDispatcherServletInitializer) 👈
[A] 调用 registerContextLoaderListener(ctx)
➜ createRootApplicationContext() : 实例化父容器
➜ ctx.addListener(new ContextLoaderListener(rootContext)) : 挂载监听器
[B] 调用 registerDispatcherServlet(ctx)
➜ createServletApplicationContext() : 实例化子容器
➜ new DispatcherServlet(childContext) : 将子容器塞进 Servlet
▼
3. 容器联姻与刷新 (DispatcherServlet 生命周期)
DispatcherServlet.init() ➔ FrameworkServlet.initServletBean()
核心代码节点:initWebApplicationContext()
- 通过 WebApplicationContextUtils 从 ServletContext 拿到父容器
- wac.setParent(rootContext) : ★父子引用正式建立★
configureAndRefreshWebApplicationContext(wac) : 触发子容器 refresh()onRefresh(wac) : 开始初始化 HandlerMapping、ViewResolver 等
三:SpringMVC 组件注册
当容器准备好后,DispatcherServlet 开始它的初始化生命周期 init() 方法,如上图我们看到最终执行了 DispatcherServlet#onRefresh 这个钩子,这标志着 Spring MVC 从 “通用容器” 向 “Web 处理器” 的最后转变。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| @Override
protected void onRefresh(ApplicationContext context) {
initStrategies(context);
}
protected void initStrategies(ApplicationContext context) {
initMultipartResolver(context);
initLocaleResolver(context);
initThemeResolver(context);
initHandlerMappings(context);
initHandlerAdapters(context);
initHandlerExceptionResolvers(context);
initRequestToViewNameTranslator(context);
initViewResolvers(context);
initFlashMapManager(context);
}
|
SpringMVC 的调用过程
执行 doDispatch
DispatcherServlet 本质上还是一个 servlet,遵循 servlet 组件的调用规则。你会发现无论是 doGet、doPost、还是 service 方法,最终都会走到这个关键的 doDispatch 方法。
DispatcherServlet.doDispatch 核心逻辑
PREPARE
1. 检查多部分请求 (Multipart)
processedRequest = checkMultipart(request);
如果是文件上传,包装 Request;否则保持原样。
MAPPING
2. 获取处理器与适配器
mappedHandler = getHandler(processedRequest); // 🚩 找 Controller 和拦截器链
HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler()); // 🚩 找对应的适配器
如果 mappedHandler 为空,直接触发 404 (noHandlerFound)。
EXECUTE
3. 拦截器与业务调用
if (!mappedHandler.applyPreHandle(processedRequest, response)) return; // 🚩 执行拦截器 preHandle
mv = ha.handle(processedRequest, response, mappedHandler.getHandler()); // 🚩 真正执行 Controller
applyPreHandle 只要返回 false,请求就此止步。ha.handle 是我们的业务逻辑所在。
RESULT
4. 后置处理与响应渲染
mappedHandler.applyPostHandle(processedRequest, response, mv);
processDispatchResult(processedRequest, response, mappedHandler, mv, dispatchException);
即使业务报错,也会进入 processDispatchResult 进行异常页面或 JSON 的渲染。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
|
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
HttpServletRequest processedRequest = request;
HandlerExecutionChain mappedHandler = null;
boolean multipartRequestParsed = false;
WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
try {
ModelAndView mv = null;
Exception dispatchException = null;
try {
processedRequest = checkMultipart(request);
multipartRequestParsed = (processedRequest != request);
mappedHandler = getHandler(processedRequest);
if (mappedHandler == null) {
noHandlerFound(processedRequest, response);
return;
}
HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());
String method = request.getMethod();
boolean isGet = HttpMethod.GET.matches(method);
if (isGet || HttpMethod.HEAD.matches(method)) {
long lastModified = ha.getLastModified(request, mappedHandler.getHandler());
if (new ServletWebRequest(request, response).checkNotModified(lastModified) && isGet) {
return;
}
}
if (!mappedHandler.applyPreHandle(processedRequest, response)) {
return;
}
mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
if (asyncManager.isConcurrentHandlingStarted()) {
return;
}
applyDefaultViewName(processedRequest, mv);
mappedHandler.applyPostHandle(processedRequest, response, mv);
}
catch (Exception ex) {
dispatchException = ex;
}
catch (Throwable err) {
dispatchException = new ServletException("Handler dispatch failed: " + err, err);
}
processDispatchResult(processedRequest, response, mappedHandler, mv, dispatchException);
}
catch (Exception ex) {
triggerAfterCompletion(processedRequest, response, mappedHandler, ex);
}
catch (Throwable err) {
triggerAfterCompletion(processedRequest, response, mappedHandler,
new ServletException("Handler processing failed: " + err, err));
}
finally {
if (asyncManager.isConcurrentHandlingStarted()) {
if (mappedHandler != null) {
mappedHandler.applyAfterConcurrentHandlingStarted(processedRequest, response);
}
asyncManager.setMultipartRequestParsed(multipartRequestParsed);
}
else {
if (multipartRequestParsed || asyncManager.isMultipartRequestParsed()) {
cleanupMultipart(processedRequest);
}
}
}
}
|
拦截器 interceptors
还有以下三段方法来自于 HandlerExecutionChain 类,它们完美诠释了责任链模式在 Spring MVC 中的应用。最精妙的地方在于,这三个方法共同构建了一个 “剥洋葱” 式的执行结构:正序进入,逆序退出。
applyPreHandle:正序拦截(守门员)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
boolean applyPreHandle(HttpServletRequest request, HttpServletResponse response) throws Exception {
for (int i = 0; i < this.interceptorList.size(); i++) {
HandlerInterceptor interceptor = this.interceptorList.get(i);
if (!interceptor.preHandle(request, response, this.handler)) {
triggerAfterCompletion(request, response, null);
return false;
}
this.interceptorIndex = i;
}
return true;
}
|
applyPostHandle:逆序执行(加工员)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
void applyPostHandle(HttpServletRequest request, HttpServletResponse response, @Nullable ModelAndView mv)
throws Exception {
for (int i = this.interceptorList.size() - 1; i >= 0; i--) {
HandlerInterceptor interceptor = this.interceptorList.get(i);
interceptor.postHandle(request, response, this.handler, mv);
}
}
|
triggerAfterCompletion:逆序清理(清洁工)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
void triggerAfterCompletion(HttpServletRequest request, HttpServletResponse response, @Nullable Exception ex) {
for (int i = this.interceptorIndex; i >= 0; i--) {
HandlerInterceptor interceptor = this.interceptorList.get(i);
try {
interceptor.afterCompletion(request, response, this.handler, ex);
}
catch (Throwable ex2) {
logger.error("HandlerInterceptor.afterCompletion threw exception", ex2);
}
}
}
|
为什么 afterCompletion 也要逆序呢?想象一下我们系统中拦截器的嵌套关系:
- 权限拦截器 (最外层)
- 日志拦截器 (中层)
- 事务拦截器 (最内层) -> Controller
- 正序进入:权限检查 -> 开启日志 -> 开启事务。
- 逆序退出:提交事务 -> 结束日志 -> 释放权限。
这种栈(Stack)式的结构保证了资源释放的安全性。比如,日志拦截器需要记录事务的结果,那么事务必须在日志结束前先提交。